
Spring Cloud Stream Reference Guide(Ditmars.RELEASE)的阅读笔记
相关内容
- 第一章:介绍
- 第二章:主要概念
- 第三章:编程模型
1 关于Spring Cloud Stream
- 它是一个框架,用于构建消息驱动的微服务应用
- 基于Spring Boot
- 借助Spring Integration 来连接消息代理(Broker)
2 主要概念
应用程序模型
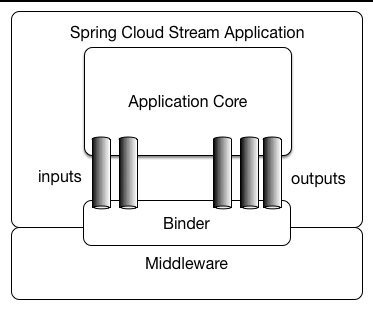
这图来自官方文档,最下面的中间件(Middleware)就是RabbitMQ,Kafka之类的消息中间件,它们和(使用Spring Cloud Stream的)应用程序通过Binder来交互,Binder需要隐藏不同中间件带来的差异.
Binder
文档是这样描述Binder的
Spring Cloud Stream provides a Binder abstraction for use in connecting to physical destinations at the external middleware.
因此,Binder就是负责接入消息中间件的(和中间件服务端上存放消息的某种设施绑定),但它不等和网络连接划等号.
Binder就像一个全功能MQ客户端,能够应付不同的MQ软件,如果需要存/取消息必须通过Binder.
持久’发布-订阅’支持(Persistent Publish-Subscribe Support)
发布-订阅的通讯模型就意味着消息的获取方式是(服务端)push.基本上消息中间件本身也是采用这种模式.要使用这种模式至少有两件事要做:
- 订阅:向MQ服务器申明自己感兴趣的内容
- 监听:准备好接收MQ服务器推送过来的内容.
这些事情的具体如何处理会因为不同的中间件而出现差异,当然处理这些差异就由Spring Cloud Stream代劳了(不然要他有何用).
官方文档在这段内容上吹了一波,比如良好的扩展性,低耦合度等,但我认为是这些本身就是
发布-订阅模型带来的福利.
消费者分组
假设有A,B两个应用都订阅了消息类型M,现在MQ服务器上有10条消息:M1,M2…M10.
由假设A,B都有两个实例,A1,A2,B1,B2.
如果不分组(或者A,B都在同一个组里),他们平分这些消息:
- A1:
M1,M5,M9 - A2:
M2,M6,M10 - B1:
M3,M7 - B2:
M4,M8
如果分组,不同组的应用都会得到所有消息:
- A1:
M1,M3,M5 ... M9 - A2:
M2,M4,M6 ... M10 - B1:
M1,M3,M5 ... M9 - B2:
M2,M4,M6 ... M10
一般来说,不同用途的消息消费者(如上面的A,B)应该有各自的组,这样A,B才能都获得完整的消息.
分组通过spring.cloud.stream.bindings.<channelName>.group来指定.
持久性(Durability)
我是结合Persistence vs. Durability这篇文章来理解
Durability这个概念的.
消息持久性涉及两个方面:
Persistence: 消息的持久性(消息不能丢失)Durability:消息容器的持久性(消息是放在消息容器里的)
第一条基本上是个消息中间件都支持,第二条属于使用问题,如果不进行某种设定,发送的消息会因为没有合适的地点存放而丢失(比如消费消息的应用比产生消息应用后运行).Spring Cloud Stream在Binder的实现层保证只要对消费者进行分组就能得到Durability保证.
分区支持(Partitioning Support)
到底啥是消息分区?我的直观映像就是:MQ服务器集群对消息的处理任务进行了细分,假设集群中有2个MQ服务器,消息分区大小为2,那么在分任务的时候,分区1上的任务由服务器1负责,分区2上的任务由服务器2负责(实际上要复杂得多,但是中心思想就是集群实例分摊任务,以提高性能).
这样一来,消息的的处理任务在MQ集群上就变成并发了,分区大小设置为多少,最大并发能力就有多少.如果不启用分区,集群上的MQ服务器只有一个在工作,其他的都是备用模式(master挂了就顶上来).
因此,分区实际上是消息中间件集群对任务的细分,启用了分区后,消息的顺序性也由全局顺序下降到分区内顺序(但这个未必是缺点,大多数时候并不需要那么强的顺序要求).
- 要在使用这个功能,消息产生和消费的应用都需要进行相关配置.
Spring Cloud Stream认为Kafka的消息分区模型很有用,但是RabbitMQ并没有这个功能,于是自己做了一层封装.让使用RabbitMQ的人也尝尝甜头,不过个人觉得还是专业的人做专业的事,需要做消息分区还是上kafka.
3 编程模型
这一部分就是告诉使用者:如果你要使用
Spring Cloud Stream,你应该这么玩.
Spring Cloud Stream定义了三个跟消息访问相关的概念:
- Source : 消息生产者提交消息的地方,对于消息系统来说,这是消息的来源
- Sink : 消息消费获取消息的地方.
- Processor : 既是Source又是Sink
从代码角度上看,谁使用了@Input谁就是Sink,谁使用了@Output谁就是Source.这两个注解是任务就是告诉框架消息通道(Channel)的名字是什么,比如:
1 | public interface Jaracks{ |
然后,需要通过@EnableBinding来触发相关配置动作.
@EnableBinding({Jaracks.class})
发消息
需要发消息,只要拿到MessageChannel对象然后调用相关的方法就行了.要获取MessageChannel对象也很简单,就是Bean注入.
比如这样:
1 |
|
或者这样
1 | public class Sender{ |
收消息
想要接受消息也很容易,写个方法,并加上@StreamListener注解.
1 |
|
- 此方法的第一个参数指明了消息的类型,涉及到序列化问题,可以由相关配置参数解决.
- 如果需要返回数据(向MQ返回数据),需要再加上
@SendTo注解,并且将方法的返回类型进行修改.
聚合
Spring Cloud Stream支持一种称为聚合(Aggregation)方式来将多个应用的输入,输出通道直接连通(不需要外部MQ服务器),但这些应用需要符合以下条件
- 应用使用单一的输出通道(
Source) - 应用使用单一的输入通道(
Sink) - 应用使用单一的输入/输出通道(
Processor)
不是很明白应用场景,就是为了省去一个独立的MQ服务器?